How to design a large scale software system that supports millions of users.
Start With A Simple Architecture
To begin building an app, we will start from the beginning. We will create a basic app with some users. The easiest way to do this is to put the whole app on one server. This is a common way to start. The app and any API's will run on a server like Apache or Tomcat. We will also use a database like Oracle or MySQL.
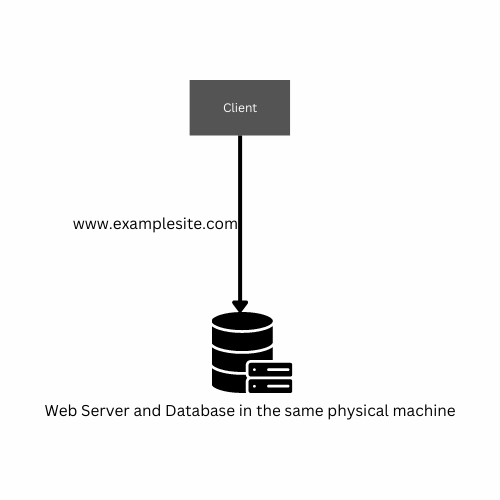
The way we have our app set up now has some problems. If the database stops working, the whole system stops working. If the server that runs the app stops working, the whole system stops working too. This means that if one part of the system breaks, everything breaks and we don't have a backup plan.
Scalability
Our system might need to handle more things, like more data or more users. To do that, we need it to be able to handle more things without making it worse for the user. This is called scalability. We can make our system handle more things by adding more resources. There are two ways to do this: scale-up or vertical scalingand scale-out or horizontal scaling. We have to decide which one to use.
Vertical Scaling
Vertical scaling means making our system stronger by adding more resources to it, like more memory or a faster processor. This can be done by upgrading the server's hardware like adding more RAM, hard drives, or network interfaces. But this can be limited by the server's operating system and the cost of the new hardware. Also, it requires shutting down the server to do the upgrade, which can cause downtime. Additionally, Scaling up also can be done by optimizing the code and queries to run faster.
On the other hand, Scaling down means removing resources from the server like CPU, memory, and disks.
Horizontal Scaling
Horizontal scaling means adding more things, like more servers, to handle more users or data. It's harder to do this than vertical scaling because it has to be planned for before building the system. It may cost more at first but it will be worth it in the long run.
We also need to think about the cost of maintaining more servers and how the code needs to be changed to work with multiple servers.
Add Load Balancer
A load balancer is a device or software that helps distribute incoming network traffic across multiple servers or resources. The primary purpose of a load balancer is to increase the availability and scalability of a network service by distributing the workload across multiple servers.
A load balancer can be a hardware device, such as a dedicated appliance or a software that runs on a general-purpose server, that uses a variety of algorithms to distribute incoming requests to multiple servers or resources.
By distributing the traffic across multiple servers, a load balancer can help ensure that no single server is overwhelmed by too many requests, which can improve the overall responsiveness and availability of a network service. Additionally, load balancer can also improve security by directing traffic to the appropriate resources, and can provide other features like SSL offloading, DDoS protection, and health checking of the servers.
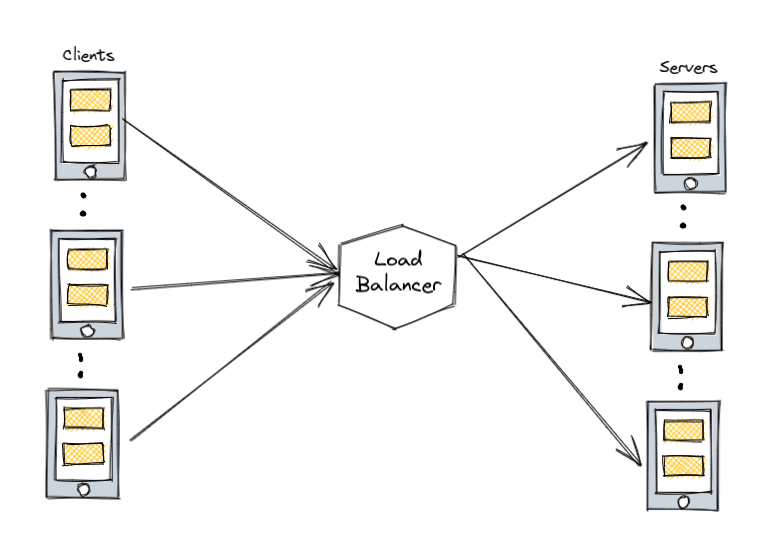
A load balancer is typically placed in between the client and the server to evenly distribute incoming traffic to multiple backend servers using different methods. This tool can be used in different locations, such as between web servers and database servers or between the client and the web servers.
HAProxy and NGINX are two common open-source load balancing software options.
When the traffic on a website increases, more servers can be added to the mix and the load balancer will take care of routing the traffic to the right place. There are different ways a load balancer can distribute traffic, such as:
- Round robin: sending requests to each server in a sequential order
- Least number of connections: sending requests to the server with the least connections
- Fastest response time: sending requests to the server with the fastest response time
- Weighted: giving more requests to stronger servers
- IP Hash: using a calculation based on the client's IP address to send the request to a specific server
Load balancing can also be done using a hardware appliance or a software alternative. Hardware appliances can make changes to the servers instantly, while software load balancing can work at both the network and application layers.
At the network layer (layer 4), the load balancer uses information from the TCP protocol to select a server without considering the specifics of the request. At the application layer (layer 7), the load balancer can use information from the request, such as the query string or cookies, to make its decision.
Database Scaling
Using a relational database management system (RDBMS) like Oracle or MySQL is an easy way to store data. However, as the amount of data grows, these systems can become difficult to manage.
There are various methods for scaling relational databases, such as:
Master-slave replication: This is a way to distribute data across multiple servers, where one server is designated as the "master" and the others are designated as "slaves." The master server is responsible for handling all the updates and changes to the data, while the slave servers act as backups. If the master goes down, one of the slaves can take its place. This method helps keep the data safe and improve performance.
Master-master replication: This is a similar method to master-slave replication, but in this case, multiple servers can act as both the master and slave. This means that any of the servers can handle updates and changes to the data, and any of the servers can act as a backup. This method is used to improve performance and reliability.
Federation: This method is used to break up the data into smaller chunks and distribute it among multiple servers. This makes it easier to manage the data and improves performance as the data grows.
Sharding: Sharding is a method of splitting a database into multiple smaller parts, called "shards." Each shard is a smaller version of the original database and contains a specific subset of the data. Each shard is then stored on a different server. This helps to distribute the load and improve performance as the data grows. The database is split into shards by a specific key, such as a user ID, and each shard is responsible for a specific range of the keys. For example, one shard might be responsible for all the user IDs between 1 and 10,000, while another shard might be responsible for all the user IDs between 10,001 and 20,000. This way, when a user requests data, it will be directed to the shard that holds the user's data and returns the result much faster.
Denormalization: This method is used to make changes to the database structure to improve performance. This can include adding extra columns or tables, or making changes to the way data is stored.
SQL tuning: This method is used to optimize the SQL queries used to access the data. This can include making changes to the queries, or adding indexes to the database to make it faster.
Master-Slave Replication
Master-slave replication is a method of scaling a database by creating multiple copies of the same data and distributing them across different servers. This allows for increased performance and availability, as well as the ability to handle increased traffic and load.
In master-slave replication, one server, called the master, acts as the primary source of data. All write operations, such as inserting, updating, and deleting data, are performed on the master. The master then replicates these changes to one or more slave servers, which act as read-only copies of the master's data.
When a change is made to the master, it is written to the binary log, a special file that contains a record of all changes made to the master. The slave servers then connect to the master and retrieve the changes from the binary log, applying them to their own copy of the data.
There are several benefits to using master-slave replication for database scaling:
- Increased performance: By distributing read operations across multiple slave servers, the load on the master is reduced, allowing for faster read performance.
- High availability: If the master server goes down, one of the slaves can be promoted to take its place, minimizing downtime.
- Easy scalability: Additional slave servers can be added as needed to handle increased traffic and load.
There are also some potential drawbacks to master-slave replication:
- Increased complexity: Setting up and maintaining multiple servers can be more complex than managing a single server.
- Data inconsistencies: In some cases, data on the slaves may not be an exact copy of the data on the master, due to replication lag or other factors.
- Limited write performance: Since all writes must be performed on the master, write performance may be limited.
Master-Master Replication
In Master-Master replication, there are two or more servers that act as Masters, each with the ability to read and write to the database. Each server maintains its own set of binary logs, and they communicate with each other to synchronize their data. When a change is made to one Master, it is written to its binary log, and then the other Master server retrieves the changes from the binary log and applies them to its own copy of the data.
There are several benefits to using Master-Master replication for database scaling:
- Increased performance: By distributing read and write operations across multiple Master servers, the load on any one server is reduced, allowing for faster performance.
- High availability: If one of the Master servers goes down, the other Master can continue to handle requests, minimizing downtime.
- Improved scalability: Additional Master servers can be added as needed to handle increased traffic and load.
However, there are also some potential drawbacks to Master-Master replication:
- Increased complexity: Setting up and maintaining multiple Master servers can be more complex than managing a single Master.
- Data inconsistencies: In some cases, data on the Master servers may not be an exact copy of each other, due to replication lag or other factors.
- Conflict Resolution: Master-Master replication can lead to conflicts when the same data is updated on multiple Masters simultaneously. This requires a conflict resolution mechanism to be in place.